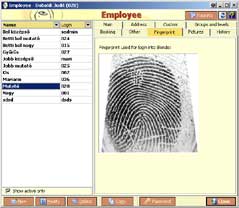
Nemrégiben egy ügyviteli rendszerbe kellett ujjlenyomat azonosítást beépítenem a felhasználók számára, előzetes költségbecsléssel. A feladat először nem tűnt bonyolultnak, de utólag már látom, hogy mennyi munkával járt, így szerintem megér egy postot.
Tudtam, hogy a Microsoft rendelkezik valami saját ujjlenyomat olvasóval, ebből gondoltam, hogy a beépítés gyerekjáték lesz és nem drága az ügyfelek számára. Az első csalódás akkor ért, amikor rájöttem, hogy a Microsoft terméke bizony nem sok mindenre használható, számomra pedig semmire. Külső alkalmazásba nem lehet integrálni, gyakorlatilag csak arra jó, hogy website-okon beírja a jelszót, ha rátesszük az ujjunkat.
Alaposabb kutatásba kezdtem. Kiderült, hogy sok gyártónak van ilyen hardvere, de szinte mindegyik csak a saját eszközéhez gyárt API-t. Mivel egy dobozos termékhez kellett ezt a funkciót kifejleszteni, nem akartam egyik hardver gyártóhoz sem elkötelezni magam, több API-t kezelni pedig még annyira sem. Így találtam rá egy biometrikus azonosítással foglalkozó szoftver cégre, aki nagyon sok típusú ujjlenyomat olvasóhoz rendelkezik egy egységes API-val.
Ekkor jött a második komoly csalódás, ugyanis már az API is pénzbe került, a Standard változata 339 EUR. Ezután még minden számítógépre kell licenszet venni (kb. 40 EUR/licensz volt, 2008 szeptembertől sokkal olcsóbb lett), ahol használni akarom és természetesen maga a hardver sem olcsó. De hasonló árakat találtam mindenhol, és a trial alapján ez a cég jónak tűnt.
Mindenféle programnyelvre (Delphi 7, VB.NET, C#, Java, C++, Access, VB6, Linux GTK stb.) volt API-juk és jó Demo programok. Az ujjlenyomat beolvasás első lépése egy egyszerű scan, amelynek eredménye egy sima kép (NImage osztály). A kép letárolása feleslegesnek tűnt, de mivel jópofa dolog az alkalmazásban megjeleníteni a képet, így mentettem azt is. A képből az algoritmus kikeresi (NFExtractor osztály) az egyedi pontokat, vonalakat, szögeket, irányokat és egy ún. minutiae-t vagy kivonatot készít belőlük (NFRecord osztály). Ebből pedig egy Byte tömb készül (NFPackedRecord). Na ezt érdemes igazából letárolni, mert az azonosításhoz úgyis ez kell és ez a legkisebb helyigényű. (3-5kB).
A keresésre és az azonosításra is külön osztály van (NFMatcher). A felismerés maga egy állítható valószínűség alapján megy. Tehát ha akarjuk, a cucc nagyon-nagyon ritkán látja két ember ujjlenyomatát azonosnak, de így előfordulhat az is, hogy bizony ismételni kell a beolvasást, mert ugyanannak az embernek kétszer egymás után beolvasott ujjlenyomatait sem találja egyezőnek. Ugyanígy beállíthatjuk úgy is, hogy gyakrabban előfordul a téves felismerés, de szinte soha nem kell ismételni a beolvasást. Minden alkalmazáshoz meg kell találni a megfelelő egyensúlyt.
Sajnos a tapasztalat az, hogy a képet is és a kivonatot is le kell tárolni. A kivonatot azért, mert ez alapján történik az azonosítás és ha egyezést keresünk, de nincs kivonat, akkor minden letárolt képből először kivonatot kell készítenünk, ami időigényes. A kép pedig két ok miatt kell: egyrészt meg tudjuk mutatni a felhasználónak (ez ugye menő), másrészt gyakran változik a képből kinyerhető kivonat technikája, ahogy fejlődik a technológia. Ez velem is megesett már. És mivel a képek tárolásra kerültek, a szoftver frissítésben ki tudtuk azt is küldeni, hogy minden letárolt képhez generálja újra a kivonatokat is.
A licenszelésük és az automatizált telepítésük külön szívás volt:
- csak online lehetett aktiválni, maximális aktiválási limittel (2 vagy 3 azt hiszem)
- egy saját service-nek folyamatosan futnia kell, hogy használni lehessen
- újraaktiválás előtt deaktiválni kellett a régi gépen és ezt elküldeni nekik, hogy a maximális aktiválások számát megnöveljék
- ha egy gép elszállt és nem tudtad deaktiválni a licenszt (ügyfeleknél azért gyakran előfordul), akkor úgy kell könyörögni nekik, hogy ugyan már hagy aktiváljál újra azzal a licensszel egy másik gépen
Az API, amivel dolgoztam, rengeteg egyéb számomra kevésbé fontos dolgot is tudott, ennek megfelelően az ára is igen magas. Ennek a cégnek egyébként van retina, arc és egyéb különleges biometrikus felismerő algoritmusa is - részben béta állapotban, sajnos mindegyik külön megvásárolandó, igen borsos áron.
Összességében a beépítés teljesen korrekten, és mindent lekezelve sokkal több időt vett igénybe, mint terveztem (kb. 5 nap). Ehhez jön még a keresés ideje, amire remélem ennek a bejegyzésnek az ismeretében másoknak már nem lesz szüksége.
Ja, és persze két ismert általános tévedés is cáfolásra került:
- Minden ujjunknál különbözik az ujjlenyomat, így ugyanazt az ujjunkat kell használni (vagy minden ujjat külön letárolni és mindegyikhez képest vizsgálni)
- A filmekben, amikor pörög a képernyőn a sok ujjlenyomat, baromság. Az algoritmus sokkal gyorsabb egy átlagos pc-n is, ha kitennénk minden képet, jelentősen lassítaná a felismerést (még esetleg 89-ben tudott úgy működni).