Nincs olyan Java programozó, aki ne találkozott volna már a Hashtable (http://java.sun.com/javase/6/docs/api/java/util/Hashtable.html) osztállyal. Egy hasznos, rengeteg célra hatékonyan használható adatszerkezetet valósít meg, ezért a gyakorlatban sokan előszeretettel használják. Van azonban néhány fontos dolog, amit mindenképpen tudnunk kell róla mielőtt saját kódunkat elkezdjük telepakolni Hashtable példányokkal és ennek következtében komoly performanciális problémákba ütközünk.
Általánosan a hash táblák elméletéről a Wikipediaban találunk infót: http://en.wikipedia.org/wiki/Hash_table
Én most ebben a postban egy lényeges ponton vizsgálnám meg a Java Hashtable implementáció működését, mégpedig az ütközések és az ezzel kapcsolatos táblaméret növelésének algoritmusánál (rehash).
Mielőtt belefognánk a rehash (resize) algoritmus elemzésébe feltétlenül meg kell értenünk a Java hash tábla alapvető működését. A hash táblában az elemek úgynevezett vödrökben (buckets) kerülnek tárolásra. Amikor egy elemet elhelyezünk a táblában, akkor megadunk egy kulcsot. Ebből a kulcsból bizonyos hash algoritmus használatával az algoritmus előállít egy memóriacímet (indexet), ahová elhelyezi magának az adatnak a mutatóját.
Az alábbi ábra ezt a struktúrát mutatja be.
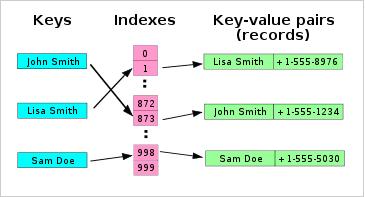
Előfordulhat azonban olyan eset, amikor a két különböző kulcshoz ugyanolyan hash érték áll elő. Ebben az esetben két különböző kulcs is ugyanarra az indexre, végső soron ugyanarra az elemre fog mutatni. Ezt hívjuk ütközésnek. Az ütközések valószínűsége csökkenthető megfelelő hash algoritmus használatával.
Tehát egy megfelelő hash algoritmusnak a következő feltételeknek kell eleget tennie:
- a hash kódnak (indexnek) minél nagyobb szórást kell mutatnia, ezzel csökkentve az ütközések valószínűségét
- minél gyorsabb legyen
A kulcs természetesen bármilyen típus lehet, ami nem null és létezik a hashCode() és equals() metódusa. A gyárilag használt típusok (Object, String, Integer, Boolean, stb.) eleve tartalmazzák ezeket a metódusokat. Java-ban minden osztály az Object osztályból származik. Nézzük meg a Java 6 API Javadoc-ban az Object osztály hashCode algoritmusát:
hashCode
public int hashCode()
Returns a hash code value for the object. This method is supported for the benefit of hashtables such as those provided by java.util.Hashtable.
The general contract of hashCode is:
• Whenever it is invoked on the same object more than once during an execution of a Java application, the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified. This integer need not remain consistent from one execution of an application to another execution of the same application.
• If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result.
• It is not required that if two objects are unequal according to the equals(java.lang.Object) method, then calling the hashCode method on each of the two objects must produce distinct integer results. However, the programmer should be aware that producing distinct integer results for unequal objects may improve the performance of hashtables.
A kiemelt részben olvashatjuk, hogy nem kötelező, hogy két különböző objektumnak a hash kódja különböző legyen. Ez sajnos a Java saját String típusánál használt hash algoritmusra kiemelten igaz. Nézzük meg a Java 6 API Javadoc-ban a String osztály hashCode algoritmusát:
hashCode
public int hashCode()
Returns a hash code for this string. The hash code for a String object is computed as
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
using int arithmetic, where s[i] is the ith character of the string, n is the length of the string, and ^ indicates exponentiation. (The hash value of the empty string is zero.)
A problémát jól mutatja a következő kódrészlet:
String s1 = new String("BB");
String s2 = new String("Aa");
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
String s2 = new String("Aa");
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
Ami ebben az esetben mindkét String hash kódjának 2112-t fog kiírni. Tehát két különböző objektumnak mégis ugyanaz lett a hash kódja. Azaz a String típus nem számít jónak az első feltételt tekintve, gyakori ütközést eredményez a hash táblában. És itt a lényeg, hogy a mindennapi programozói gyakorlatban a hash táblákban kulcsként nagyon gyakran String-eket használunk, amiknél nagy az ütközés valószínűsége.
Természetesen lehetőségünk van a hash algoritmus javítására, amennyiben saját típust hozunk létre és (felül)definiáljuk a hashCode() függvényt, ezáltal csökkentve az ütközések valószínűségét.
További probléma a Java-s hash kódokkal, hogy azok int típusúak, azaz 32 bit hosszúak, ami eleve egy elég alacsony korlát. Így maximum 4.294.967.295 különböző hash kódot eredményezhetnek. A jövőben valószínűleg szükség lesz a 64 bites (long) hash kódok használatára.
Kicsit elkanyarodtunk a témától, ezért térjünk vissza a Java hash tábla implementációhoz. Tegyük fel, hogy a fenti két String-et („BB”, „Aa”) szeretnénk kulcsnak használni egy hash táblában elemek tárolásához.
String s1 = new String("BB");
String s2 = new String("Aa");
Hashtable h = new Hashtable();
h.put(s1, "value1");
h.put(s2, "value2");
Ekkor fellép a fent részletezett ütközés. Ezt a Java úgy oldja fel, hogy az egyes vödrök tulajdonképpen láncolt listát jelentenek, és ezt a listát bővíti ütközéskor. Azaz amikor a második elemnek meghatározza a helyét (indexét/hash kódját), akkor látja, hogy ott már van egy elem, ezért az új elemet a már létező elem elé láncolja a kulccsal együtt. Amikor valaki get() metódussal szeretné az elemet megtalálni, akkor a láncon addig megy amíg az adott kulcsot meg nem találja és az ott tárolt értéket adja vissza. Ezt az ütközés-feloldást hívjuk láncolásnak (chaining). Más – hatékonyabb – algoritmusok is léteznek az ütközés feloldására, ezekről bővebb információt a fenti Wikipedia oldal tartalmaz.
Java-ban a hash táblának két fontos induló paramétere van:
- induló kapacitás (initial capacity): az elemek tárolására szolgáló "vödrök" (buckets) száma induláskor. Az egyes tárolásra kerülő objektumok kerülnek a vödrökbe. (Ne felejtsük el, hogy az egyes vödrökön belül láncolt listákban tárolódnak az elemek!)
- telítettségi faktor (load factor): a vödrök számának és a foglalt vödrök számának aránya. Érdekes, hogy ez akár át is lépheti a 100%-ot, ugyanis egy vödörben ütközés esetén több elem is tárolásra kerül a láncolt listában. Amikor egy új elem berakásakor átlépi a telítettség ezt a faktort, akkor a tábla mérete (a vödrök száma) automatikusan növekszik és lefut a rehash algoritmus.
Amikor Java-ban leírjuk a
Hashtable ht = new Hashtable();
utasítást, akkor egy 11 vödörből álló 0.75-ös telítettségi faktorú hash tábla jön létre.
Az általános konstruktor forráskódja a következő:
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: +loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
}
Nézzük meg a Hashtable forráskódjában, hogy mit csinál, amikor egy új elemet berakunk:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
return null;
}
A kiemelt részben látszik, hogy az index meghatározásához felhasználja a tábla kapacitását. Ez kezdetben az induló kapacitás, majd minden automatikus növeléskor ez
N * 2 + 1 értékre nő, ahol N a régi kapacitás. Továbbá látszik, hogy amennyiben az elemek száma eléri vagy meghaladja a kapacitás x telítettségi factor (=threshold) értéket, akkor automatikusan elindul a rehash algoritmus, ami elvégzi a tábla kapacitásának növelését.